引入
从老师给出的题目中选出该课题后。首先便浮现以下几个问题:
- 要在什么类型游戏下使用LLM实现敌人的AI?
- AI要全权接管敌人AI,还是介入部分,又要介入哪个部分呢?
- 因为LLM返回结果需要一定时间,且结果有不确定性,要怎么解决?
在第一个问题上,我最终选择2d俯视角射击游戏。他对于我们而言足够简单,特别是在有AI辅助编写代码下,可以快速完成原型开发。而在关键的敌人身上也只有移动和射击两个基本操作,但是却可以设计出足够复杂的行为来体现LLM的作用。
随后我采用有限状态机混合LLM的方式来驱动敌人的行动。现阶段LLM肯定不能时时刻刻调用来确定敌人的行动,应该像人体一样:感官收集信息,由大脑进行决策,又有小脑,脊髓和肌肉记忆负责简单动作和反射。设计感知模块,决策模块,执行模块,由LLM担任敌人AI的指挥官。
最后通过提示词设计,让LLMAPI返回Json格式结果,限定了其输出,一定程度上保证了结果的准确性。同时在客户端验证结果,设计非法回复处理。
开发环境搭建
由于小组里共有三人可以负责程序的开发,我决定引入开源项目来解决敌人寻路问题。先是了解到unity的packages中有ai.navigation包集成了A*的实现,可以简化敌人寻路AI开发。又发现navigation对于2d游戏的实现不佳。通过网络搜索和询问AI最后引入了navmeshplus来支持2d寻路。
所以最终初始环境为:
- unity 2022.3.6f1c1
- package unity.ai.navigation": “1.1.7”
- “com.h8man.2d.navmeshplus”: “https://github.com/h8man/NavMeshPlus.git#master"
项目架构设计
2d俯视角游戏基本设置
- PlayerController
基本玩家控制脚本,只有移动和射击两种操作。 - SmoothFllowCamera
简单相机跟踪 - HealthInteractor
即可以处理玩家又可以处理敌人的血量变化和交互的脚本。 - Bullet
子弹预制体的MonoBehaviour脚本
LLM API调用
- DeepSeekChatManager 调用DeepSeep大模型API的模块。
核心模块,敌人AI
参考人类思考和行动的方式,进行了分层设计,大致为感知,决策,执行层。
- 中间桥梁感知层EnvPerceiver
通过该脚本检测环境信息,包装为自然语言传递给下流决策层进行决策,和给执行层锁定追踪对象,寻找掩体。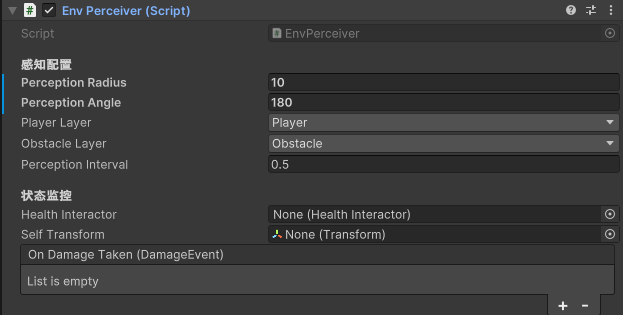
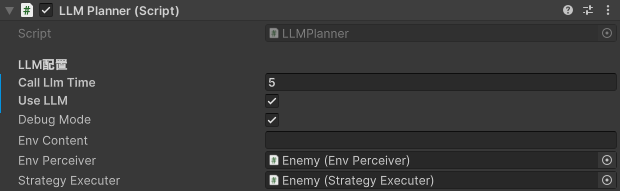
- 顶层决策层LLMPlanner
接收感知层信息,调用LLMAPI调用模块,传达命令给执行层。
- 底层执行层,共两层
- StrategyExecuter
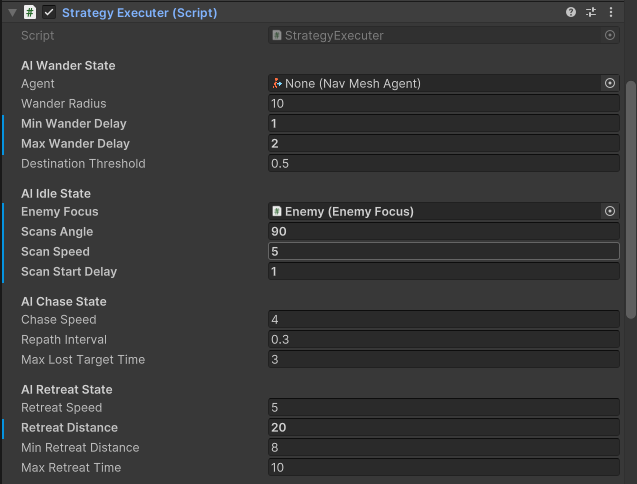
接收命令,发出状态切换的指令。 - 低级执行层,预编写的各种状态
- IdleState待机状态
- RetreatState撤退状态
- ChaseState追击状态
- WanderState游荡状态
- StrategyExecuter
最终结果
实际开发中的难点
根据自己开发的部分和小组成员的反馈。在AI辅助开发情况下,难度不高。主要是未考虑其他条件和提供给AI的实际项目上下文不足导致的bug。如:
- API调用没有使用异步或者协程导致阻塞主线程。
- 空引用不存在的模块。
- API调用超时,非法输出处理。通过引入状态延续,默认状态机制解决。
实际最困难的部分,反而是状态机部分。撤退状态开始时涉及了掩体躲避和反击,但是用AI编写的代码不和预期,最终因为时间关系,只能改为单纯尝试远离玩家的设计。 还有一些参数的设置问题,为了控制API调用频率,降低成本。我们引入了API调用频率控制的参数。太慢显得敌人呆呆,太快消耗token。最后引入根据环境是否高压,动态控制思考调用频率,即减少token消耗,又保留敌人的高智能。
总结
这次架构设计让我深刻理解了“确定性系统”与“非确定性 AI”的结合之道。通过将 LLM 限制在“策略层”,我们既获得了智能的战术决策,又保留了传统代码的稳定性。
但是还有一些未来可以改进优化的地方。
最开始是准备引入unityPackage的ML-Agent包,在底层执行使用强化学习让敌人行为更智能。考虑到DDL要到了,需要的python方面AI编码和训练时间,最终没有加入。
目前只有一个敌人,而且代码只考虑孤军作战的情况。放多几个敌人是没有相应的合作行为。未来或许可以加入指挥官系统,考虑多ai合作。
考虑给LLM更多的权限,比如更多状态,放开状态参数调整权限,让有限状态产生更多变化。